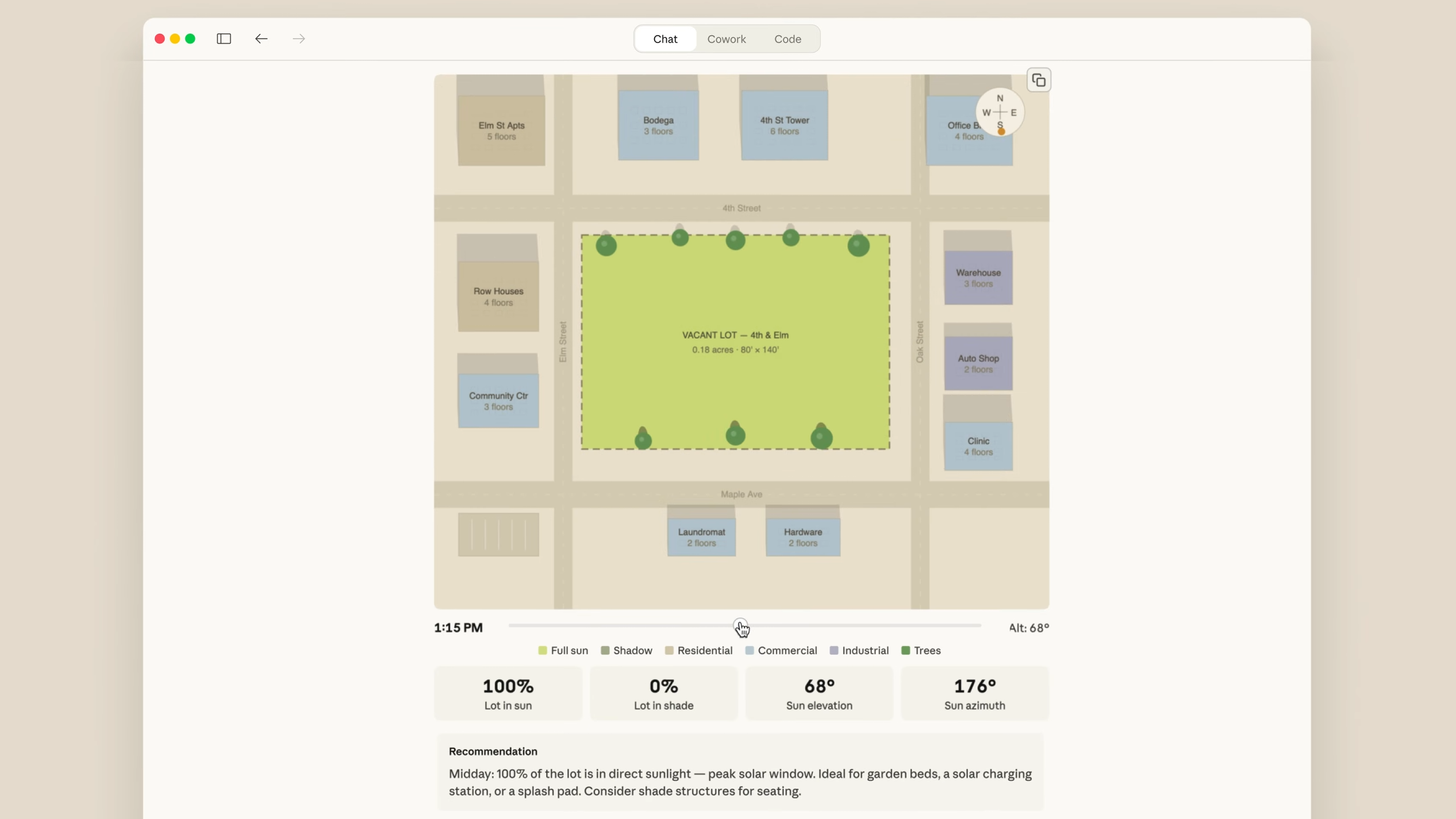
Does a smarter model mean better code? Anthropic says "no — the harness determines the outcome." That's what they published in their official engineering blog on March 24, 2026.
What is this about?
This post by Prithvi Rajasekaran from Anthropic Labs started with tackling two problems simultaneously: getting Claude to produce beautiful frontend designs, and getting it to build complete applications autonomously over hours.
The core insight is straightforward: the same model produces wildly different results depending on harness design. Anthropic's earlier "Building Effective Agents" blog already established the principle of "find the simplest solution possible, and only increase complexity when needed", and this new post is the practical story of applying and evolving that principle.
Here, "harness" means the entire execution environment wrapping an LLM — prompts, tool connections, inter-agent collaboration structures, feedback loops, everything outside the model itself. As Aakash Gupta puts it, if the model is the engine, the harness is the car — the best engine is useless without steering and brakes.
This topic is hot right now because the entire industry is converging on the same conclusion. Manus rewrote their harness 5 times in 6 months. LangChain redesigned Deep Research 4 times. Vercel removed 80% of their agent's tools and got better results. OpenAI also formalized the concept of harness engineering.
What changes?
The Anthropic blog identifies two core problems.
First, Context Anxiety. Agents lose coherence as context windows fill up. Even worse, when they "feel" they're approaching limits, they tend to wrap up work prematurely. This was so severe with Sonnet 4.5 that they opted for full context resets.
Second, Self-evaluation failure. When you ask an AI to evaluate its own work, it responds with confident praise — even when the quality is obviously mediocre. This was especially pronounced for subjective tasks like design.
To solve both, Anthropic drew inspiration from GANs (Generative Adversarial Networks) and separated the Generator from the Evaluator.
| Traditional (single agent) | Anthropic's approach (separated) | |
|---|---|---|
| Self-eval | Makes it and judges it → always generous | Different AI for making vs. evaluating |
| Design quality | Safe, predictable layouts on repeat | Iterative improvement against criteria, museum-quality attempts |
| Long tasks | Loses coherence when context fills | Planner-Generator-Evaluator 3-tier structure |
| Cost vs quality | 20min, $9 — core features broken | 6hrs, $200 — fully working app |
For the frontend design experiment, Anthropic created 4 evaluation criteria: design quality, originality, craft, and functionality. For originality, they specifically noted that "unmodified stock components or telltale AI slop patterns (like purple gradients over white cards) fail here". They explicitly penalized AI-looking design.
The Evaluator was given Playwright MCP to navigate the live page, take screenshots, and evaluate. Over 5-15 iterations, scores improved, and in one experiment building a Dutch art museum website, the 10th iteration produced a creative leap — a 3D room with CSS perspective, artwork on walls, and doorway-based navigation.
The key takeaway: 3 stages of evolution
- Stage 1: 2-Agent Harness (Nov 2025)
Initializer + Coding Agent. Decomposed work into features with context resets between sessions. Sonnet 4.5 based. Even this alone vastly outperformed baseline agents. - Stage 2: 3-Agent Harness (Opus 4.5)
Planner + Generator + Evaluator. Expanded one-line prompts into 16-feature, 10-sprint specs. Contract negotiation before each sprint, then build-evaluate loops. Built a 2D retro game maker in 6 hours at $200 — incomparable to the solo agent (20min, $9) whose core features didn't even work. - Stage 3: Simplified Harness (Opus 4.6)
Removed sprint structure, reduced evaluation to a single pass at the end. Possible because Opus 4.6 was smarter. Built a browser DAW in about 4 hours at $125. - The real lesson: every harness component encodes an assumption about what the model can't do alone
When models improve, those assumptions must be re-tested. Strip away what's no longer needed, add new components for new possibilities. Anthropic practiced this explicitly — when Opus 4.6 dropped, they removed sprint decomposition and added prompting for built-in AI features instead.
Anthropic's key quote
"The space of interesting harness combinations doesn't shrink as models improve. Instead, it moves, and the interesting work for AI engineers is to keep finding the next novel combination."
LangChain's Lance Martin compared this to Richard Sutton's "Bitter Lesson" — the principle that general methods leveraging computation ultimately beat hand-crafted systems now applies at the application layer too. "Over time models get better and you're having to strip away structure, remove assumptions and make your harness simpler".
Related post
Working Reference's existing post Harness Engineering — Taming AI Coding Agent Wild Horses covers practical frameworks like Commands, Skills, and Hooks. This article focuses on Anthropic's official blog design philosophy and evolution story — a separate reference.