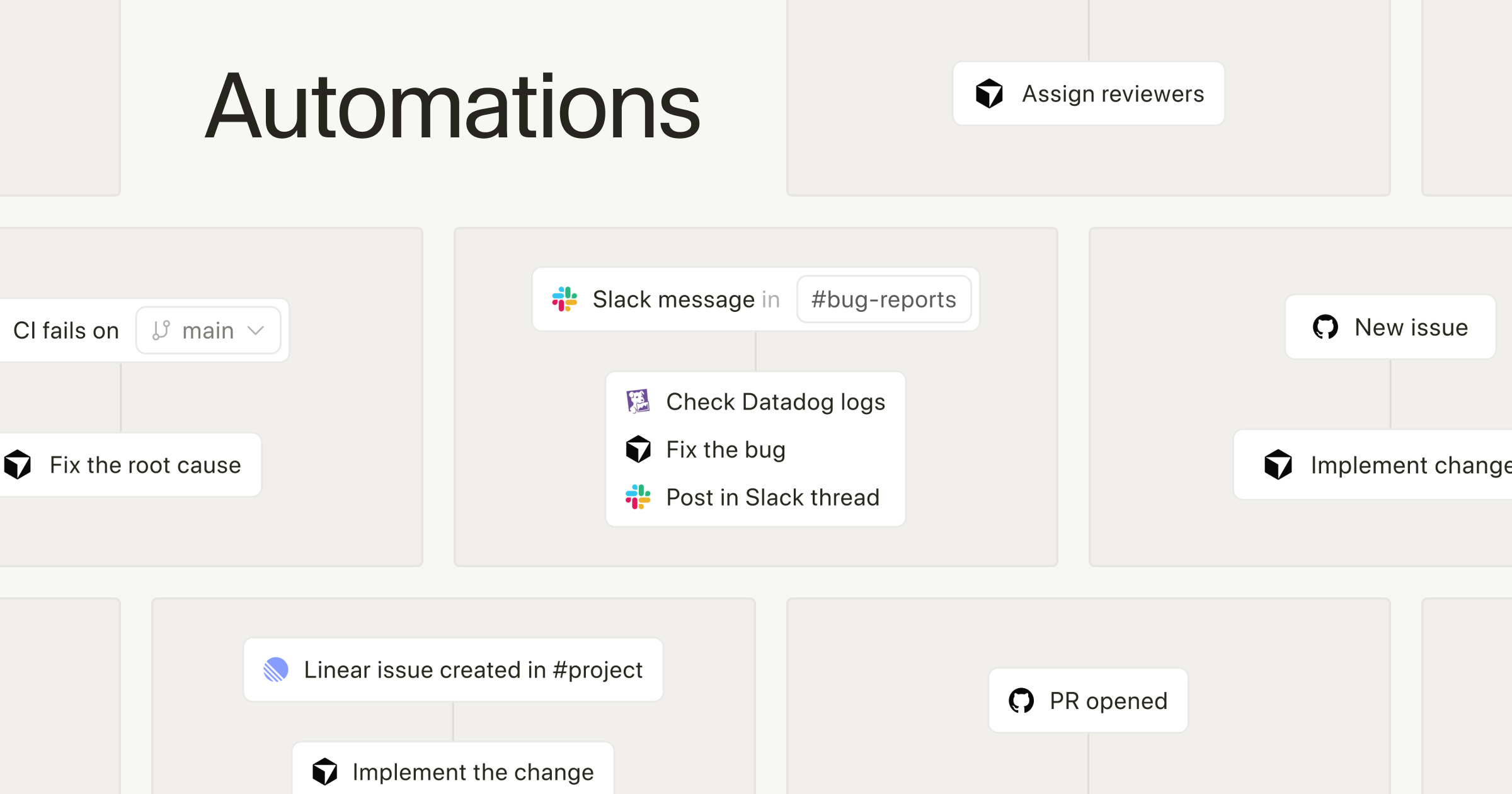
Just a year ago, "we support RAG" was the killer feature for agent tools. But now? ChatGPT does it, Claude does it, even free chatbots do it. Web search, document-based responses, memory — all table stakes now. So what should agent development tools differentiate on?
What Is This About?
A post by n8n's technical analyst Andrew Green in April 2026 stirred up quite a conversation. The core argument is simple — the criteria used to evaluate agent tools last year are no longer valid in 2026.
The 2025 Enterprise AI Agent Development Tools report from n8n evaluated tools based on building blocks like RAG, memory, tool calling, and evaluations. But within a year, all these capabilities became "expected." Claude's Projects, ChatGPT's Apps, native Skills.md — LLM services themselves have risen to near-agent level.
MCP (Model Context Protocol) followed a similar trajectory. It saw explosive growth, then lost trust after incidents like OpenClaw's security issues. Green flatly stated that "no sensible organization would consider OpenClaw." The entire agent tool market is being reshuffled.
Why now?
Google Opal, OpenAI Agent Builder, Microsoft Copilot Studio — big tech has entered the no-code agent builder market directly. Startups must now either innovate faster or compete on an entirely different axis.
What's Actually Changing?
The biggest shift Green proposes is the evaluation axis itself. Last year it was "codability vs integrability." In 2026, it becomes "codability vs enterprise-readiness."
The integrability axis (number of API integrations, connectors) is no longer a differentiator. Instead, observability, data loss prevention, agent code sandboxing, killswitches, and role-based access control are the new benchmarks.
| 2025 Criteria | 2026 Criteria | |
|---|---|---|
| Core Axis | Codability vs Integrability | Codability vs Enterprise-Readiness |
| RAG / Memory | Differentiator | Table stakes |
| MCP Integration | Innovative feature | Security verification required |
| Integration Connectors | Key comparison metric | Absorbed into codability axis |
| Deterministic Control | Nice to have | Essential — compensates for AI non-determinism |
| Observability / DLP | Enterprise-only | Baseline requirement for all orgs |
Particularly noteworthy is the spotlight on deterministic control. Green shared results from running a security agent 50 times on identical code, revealing inconsistent vulnerability detection across runs. Hardcoding "always check VirusTotal" is far more reliable than letting AI "reason" its way through the check.
According to Composio's analysis, this is also a "brain vs body" problem. Agent reasoning logic (brain) is well-handled by frameworks like LangChain and CrewAI, but the real bottleneck remains integration, authentication, and execution (body) with external apps. Securely managing authentication for thousands of users while handling non-deterministic agent workflows is a completely different challenge.
Agent Frameworks: Who's Winning Right Now?
Synthesizing GuruSup's comparison and Medium's practical tier list, each framework has carved out a clear position.
| Framework | Core Approach | Strength | Limitation |
|---|---|---|---|
| LangGraph | Directed graph + state checkpointing | Debug visualization, time-travel, human-in-the-loop | Overkill setup for simple workflows |
| CrewAI | Role-based team metaphor | Start with 20 lines, rapid prototyping | State management limits at scale |
| OpenAI Agents SDK | Agent-to-agent handoffs | Clean API, built-in guardrails | Locked to OpenAI models |
| Google ADK | Hierarchical agent tree | A2A protocol, multimodal | Ecosystem still early |
| n8n + AI Nodes | Visual workflow + LLM | No-code, 800+ integrations | Weak for non-deterministic agent workflows |
| AutoGen/AG2 | Conversational agent teams | Agent debate and iteration | Token costs spike quickly |
For solopreneurs, a practical strategy is ramping up complexity from n8n (no-code) to LangChain (general-purpose) to CrewAI (multi-agent). In most cases, "a well-prompted GPT-3.5 agent in a 100-line Python script often outperforms a complex multi-agent CrewAI orchestration" — advice born from real production experience.
The Essentials: How to Get Started
- Re-evaluate your current tools
Check whether the differentiators that drove your agent tool choice last year still hold. If RAG, memory, or web search was the only reason, it's time to reconsider. - Lay down deterministic logic first
Before expecting agents to figure things out, hardcode the checkpoints they must pass. "Always check this API," "Always output in this format" — these guardrails matter. - Build an enterprise-readiness checklist
Observability, killswitch, rollback, agent sandboxing, role-based access control — check how many your current tool supports. - Match framework choice to team context
Non-coding team? n8n. Complex branching? LangGraph. Quick prototype? CrewAI. There is no "best tool" — only "the right tool for your team." - Consider separating brain from body
Design reasoning logic (brain) and integration/auth/execution (body) as separate layers. This way, switching frameworks won't break your execution layer. Composio is one example of this approach.
Vibe coding and agent building are different things
Green drew a clear line — "coding agents (Claude Code, Codex) are for coders, and they're a separate domain from agent building tools." Expecting non-developers to build and maintain production apps through vibe coding is unrealistic.